

If you haven’t visited Part I, I highly recommend you go through it for a better understanding of this blog.
Let’s continue 🤠
What is Property Based testing?
Before delving into property based testing, it’s important to understand example-based testing.
Traditional, or example-based testing specifies the behaviour of your software by writing examples of it, each test sets up a single concrete scenario and asserts how the software should behave in that scenario. The problem with example-based tests is that they end up making far stronger claims than they can demonstrate. Consider unit testing as an example. In this method, developers test a single input scenario to ensure a comprehensive evaluation of a specific function or condition’s behaviour. It is a widely employed testing approach preferred by most developers.
Meanwhile, Property-based tests take these concrete scenarios and generalize them by focusing on which features of the scenario are essential and which are allowed to vary and generating numerous example-based scenarios and tests in the loop. Property-based testing relies on properties. It checks that a function, program or whatever system under test abides by a property. Property-based tests are designed to test the aspects of a property that should always be true. They allow for a range of inputs to be programmed and tested within a single test, rather than having to write a different test for every value that you want to test.
Let’s test a code and learn practically. The following code is a code for finding factorial for a particular number.
Let’s now write a few unit tests
All the unit tests will pass and give 100% line coverage. Well, let’s now use property-based testing.
This test will fail because the code is incorrect, the factorial of the prime number is not the exact prime number itself. But in unit testing, as the user considered only value 2 for testing the prime numbers, he couldn’t uncover the bug whereas property-based testing has uncovered the bug as it generates many inputs and test the code.
This is a small example to get the gist of property-based testing as the code gets more complex property-based testing will be more useful.
How can you use property based testing for test automation and E2E tests?
Earlier, we explored an example demonstrating the utilization of property-based testing in unit tests. However, we have also discussed the advantages of end-to-end tests over unit tests. End-to-end tests involve sending API requests to the application, utilizing a production-like database, and asserting the response. Our objective is to generate these API requests using property-based testing. Traditionally, developers or QA teams would write end to end tests using example-based testing. However, we are now seeking to employ property-based testing to generat a diverse range of inputs, specifically in the form of API requests and provide a wide range of inputs or in-case here API requests.
The main aspect of property based testing is the property on which the test is evaluated. So let’s discuss the properties of an API
- Request URL
- Request Method
- Request Parameters and their types
- Request JSON structure and their types
- Response status code
- Response JSON structure and their types
The main property out of these would be Response status code and Response JSON structure on which the evaluation happens, the rest act as conditions for inputs.
But how do we get this info in a structured way? is there any format available? Yes🤠 Have you heard of OpenAPI schema or graphQL schema or GRPC proto file? These methods provide structured approaches to obtain the properties of an API systematically. Now, let’s explore the structure and appearance of an OpenAPI schema.
If you believe that obtaining the properties and employing property-based testing will suffice, you might be surprised to learn that we require a few additional components. Input generation plays a pivotal role in this context. As we aim to control the number of tests generated and avoid creating an excessive amount of unnecessary tests, we must exercise caution in what we generate. It is essential to consider a wide range of edge cases and uncover potential bugs. Luckily, there are several techniques available to assist us in achieving these goals 😁.
Fuzzing: Fuzzing provides a wide range of built-in strategies for generating inputs. These strategies define the type, structure, and characteristics of the input data used in your property-based tests. For example, integers(), text(), lists(), or dictionaries() are some of the strategies available. Fuzzing utilizes these input strategies to generate a large number of random inputs for testing. The generated inputs cover a broad spectrum of possibilities, including edge cases, boundary values, and random or unexpected data.
Shrinking Algorithm when Random inputs are generated and fed into property-based testing there would be a failure case. Like it was explained before the input generation must be such that it would generate more failure test cases. So once a failure occurs this algorithm this shrinking Algorithm is used to generate more failure test cases.
Shrinking is the mechanism by which a property-based testing framework can be told how to simplify failure cases enough to let it figure out exactly what the minimal reproducible case is.
Sometimes the input required to find a failure can be fairly large or complex. Finding the initial failing case may have required hundreds of attempts, and it may contain vast amounts of irrelevant information. The framework will then attempt to reduce that data set by shrinking it. It generally does so by transforming all the generators used and trying to bring them back towards their own zero point:
- A number tends to shrink from floating-point values towards integers, and integers tend to shrink towards the number 0.
- binaries tend to shrink from things full of bytes towards the empty binary (
<<>>) - lists also tend to shrink towards the empty list
elements([A,B,C])will shrink towards the valueA
let’s look at an example
If we look at the example when a randomly generated value(here it is 7) is tested if failed and then the minimal failing example is found out by decreasing the number. Then these cases can be stored as examples so that they will be prioritised over other values and these minimal failing examples are fed into the feedback loop.
Feedback loop When a test fails and shrinking is applied to it, then the minimal failing example is fed back into the input generator by using statistical techniques like similarity metrics and dynamically guide the generation of test cases based on past failures.
This process enhances the efficiency and effectiveness of property-based testing by incorporating knowledge from past failures. Even when a scenario passes successfully, sending a feedback loop can still be beneficial, especially when utilizing the API schema’s ability to link APIs. This feature allows us to define which APIs should be tested after a particular one, providing the opportunity to explore stateful testing.
By establishing links between APIs in the schema, we can create a chain of interrelated API calls. Once an API is tested and its response is obtained, the feedback loop ensures that the same response is utilized as input for the linked API. This enables stateful testing, where the state of the system evolves dynamically based on the sequence of API interactions.
There are a few more techniques like swarm testing which will help in load testing the application for race conditions, concurrency errors etc
Swarm Testing: Swarm testing is a distinct approach to testing that focuses on executing tests concurrently with a large number of virtual users or clients to simulate real-world scenarios and load conditions. It aims to identify performance bottlenecks, scalability issues, and potential failures that may occur when multiple users interact with the system concurrently.
Swarm testing can be used to complement property-based testing. While property-based testing focuses on generating diverse inputs and validating the expected behaviour, swarm testing can be employed to stress test the API endpoints by simulating a large number of concurrent requests and analyzing the system’s response times, throughput, and overall performance.
Let’s make a design out of this theoretical approach
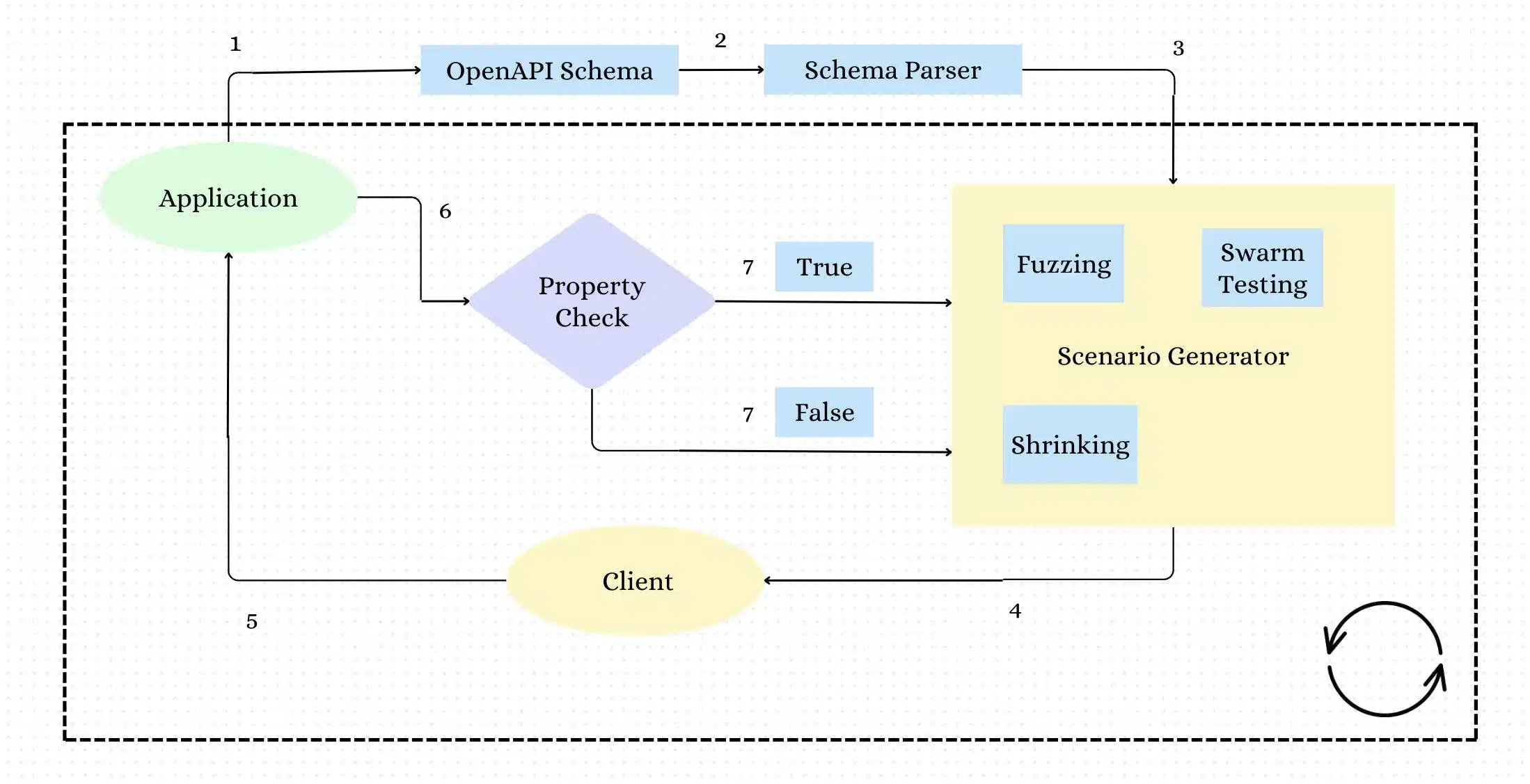
- The application or the user provides OpenAPI Schema
- Schema Parser will parse the schema and provide all the input properties and the main property which is response codes to the input generator.
- The input generator will use fuzzing to use the input properties and create a good data set which contains edge cases.
- Input generator provides the scenario content to the client and the client prepares a request for the application.
- The client hits the application with the request.
- The response is validated.
- If the response is valid then feedback will be sent to the generator if we define stateful testing in schema then the response is directly used as input for the next scenario else a random scenario is generated.
- If the response is invalid then feedback is sent to the shrinking algo in the generator which influences the fuzzing to create similar scenarios.
- This loop continues till we reach the desired no of test cases that we define.
This is the process through which we can create comprehensive end-to-end (E2E) scenarios or API requests that thoroughly test our application. However, a question arises: how do we store these requests for future use and ensure that the database remains in the same state as during the initial testing? Fortunately, there is a solution to address these concerns 🤫.
How is Keploy useful to create a complete E2E testing platform with property-based testing?
Keploy is an open-source tool that generates test files and data mocks from API calls. Keploy understands the exact API call and the correct response to reply with, including dynamic elements. So if you’re using any external service like Databases, third-party vendors, cloud services, etc Keploy will automatically mock their response hence eliminating the need for external dependencies. Cut down on flaky tests with stable, repeatable environments. Keploy does the following things
- Keploy records the API request which is sent and also external dependency calls like database calls or HTTP calls etc
- Keploy will run the recorded tests and supply the previously recorded dependency calls for the tests which are being performed. This will create the same environment in which the test has been recorded.
- Once the test run is done test report is provided with coverage data.
- It can be used as a regression suite too.
This aspect brings a sense of completeness to the process of creating automated end-to-end (E2E) tests using property-based testing. The scenarios generated by property-based testing are recorded and can be replayed to effectively test your application.
During the development phase, developers often make requests to the application to validate its expected behaviour. These requests can be recorded and utilized as a means of evaluating the developer’s progress, serving as an alternative to unit tests. By leveraging the recorded requests, developers can verify whether the application is functioning as intended during the development process.
Is property-based testing + Keploy better than AI in test automation?
This topic sparks debate, but I’d like to share my experience with AI in creating end-to-end test cases. While the testing platform isn’t solely focused on creating end-to-end scenarios, it also encompasses test case maintenance, re-running tests, maintaining code coverage, and more. These tasks often require tools like Keploy, which are currently beyond the capabilities of AI.
When it comes to scenario creation, I’ve explored leveraging ChatGPT, one of the most advanced AI models available, to generate test scenarios. However, in comparison to test cases generated by property-based testing, the AI produced a limited number of test cases, primarily focusing on what a human might consider as edge cases. In contrast, property-based testing aims to cover a wider range of scenarios, including what humans may perceive as edge cases.
It’s important to note that this remains an ongoing discussion. While AI has the potential to detect more bug-intended inputs, which property-based testing achieves through techniques like shrinking and the feedback loop, an ML/AI model could accelerate the process with fewer feedback iterations.
In conclusion, AI can enhance the creation of automated end-to-end tests using property-based testing, but it cannot entirely replace the entire testing toolset, in my opinion.
With that, we’ve come to the end of this blog, which aims to introduce various techniques for simplifying and streamlining testing processes. I encourage readers to share their thoughts on the following question in the comments: "Is property-based testing + Keploy better than AI in test automation?" Let’s engage in a meaningful discussion! 🙂
